
In today’s fast-paced digital arena, the pressure to build systems that can handle massive scale while maintaining reliability is ever-mounting. As user bases swell into the tens of millions and beyond, the need for distributed systems capable of withstanding such demands becomes paramount. But fear not, fellow explorer of the digital wilderness, for I’m here to guide you through the labyrinth of distributed system design, with a particular focus on scaling to accommodate 100 million users and beyond, all while ensuring site reliability remains steadfast atop the towering peak of technological prowess.
- Understand the Basics: Before delving into distributed system design, it’s crucial to grasp the fundamental concepts. Familiarize yourself with terms like scalability, fault tolerance, consistency, latency, and throughput. A solid understanding of these basics will provide you with a strong foundation to build upon.
- Identify Requirements and Constraints: Every distributed system is unique, with its own set of requirements and constraints. Start by defining the goals and objectives of your system. What problem are you trying to solve? What are the performance expectations? What are the scalability requirements? Consider factors such as data volume, access patterns, and expected growth.
- Choose the Right Architecture: Distributed systems come in various shapes and sizes, each with its own architecture suited for specific use cases. Common architectures include client-server, peer-to-peer, and microservices. Evaluate the pros and cons of each architecture in relation to your requirements.
- Design for Scalability and Fault Tolerance: Scalability and fault tolerance are two key pillars of distributed system design. Design your system with scalability and fault tolerance in mind from the outset to avoid costly redesigns later on.
- Address Data Consistency and Concurrency: In distributed systems, maintaining data consistency across multiple nodes can be challenging due to the inherent latency and network partitions. Choose an appropriate consistency model based on your application’s requirements.
- Handle Communication and Coordination: Effective communication and coordination are essential for distributed systems to function seamlessly. Choose suitable communication protocols and message formats for inter-node communication.
- Test, Monitor, and Iterate: Once you’ve designed your distributed system, it’s crucial to test it rigorously under various conditions to uncover potential issues and bottlenecks.
Now, let’s navigate through the specifics of scaling to accommodate 100 million users and ensuring site reliability.
- Setting Sail with Kubernetes: Kubernetes stands as our stalwart companion, orchestrating our fleet of containers with precision and grace. With Kubernetes at the helm, we can scale our infrastructure seamlessly, deploying and managing microservices with ease, and ensuring high availability even in the face of tumultuous seas.
- Continuous Deployment: Charting a Course for Agility: With continuous deployment practices in place, we can navigate these waters with confidence, pushing updates and enhancements to our system with minimal disruption.
- Building a Robust Infrastructure: A sturdy infrastructure forms the bedrock of any distributed system. With Kubernetes as our foundation, we can erect a fortress capable of withstanding the onslaught of traffic from 100 million users and beyond.
- Choosing the Right Databases: Whether it be SQL or NoSQL, each database brings its own strengths and weaknesses to the table. By judiciously selecting and architecting our database layer, we can ensure data integrity and performance at scale.
- Harnessing the Power of Kafka: Kafka emerges as a beacon of hope amidst the storm, enabling us to stream vast volumes of data in real-time, ensuring smooth communication and coordination across our distributed system.
- Navigating the Seas of Monitoring: With robust monitoring and observability tools in place, we can peer through the mist and gain insight into the inner workings of our distributed system.
Here’s a simplified diagram illustrating the components and interactions within a distributed system designed to accommodate 100 million users, emphasizing scalability, reliability, Kubernetes orchestration, continuous deployment, infrastructure, databases, Kafka for messaging, and monitoring:

In this diagram:
- The load balancer distributes incoming traffic across multiple Kubernetes clusters.
- Each Kubernetes cluster consists of nodes hosting microservice pods managed by Kubernetes.
- Microservices interact with databases (SQL/NoSQL) for data storage and retrieval.
- Kafka clusters facilitate real-time messaging and event-driven communication between microservices.
- Monitoring tools such as Prometheus, Grafana, and Jaeger provide visibility into the system’s health, performance, and behavior.
This diagram illustrates a distributed system design to handle high traffic volumes, ensure scalability, maintain reliability, and facilitate continuous deployment, all orchestrated within Kubernetes clusters.
In conclusion, the journey of distributed system design is not for the faint of heart. It requires courage, resilience, and a keen sense of navigation. But with Kubernetes as our guide, continuous deployment as our compass, and a sturdy infrastructure as our vessel, we can chart a course to success, scaling to accommodate 100 million users and beyond, all while maintaining site reliability at the helm. So hoist the sails, my fellow adventurers, and let us set forth into the uncharted waters of distributed system design, where the treasures of scalability and reliability await those bold enough to seek them. Fair winds and following seas!
References:
- Kubernetes: https://kubernetes.io/
- Apache Kafka: https://kafka.apache.org/
- Prometheus: https://prometheus.io/
- Grafana: https://grafana.com/
- Jaeger: https://www.jaegertracing.io/
Further reading:-

Web Vitals – What are FCP, LCP, FID, TBT, TTFB?
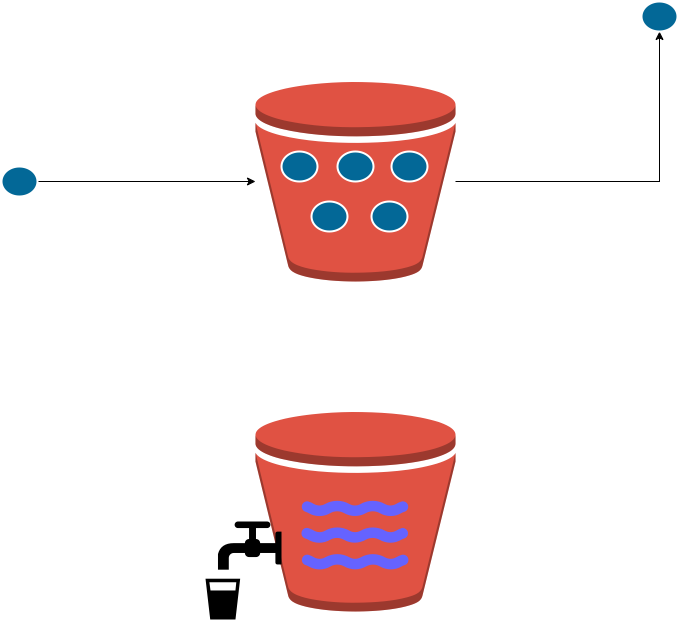
Rate Limiting – Token and Leaky Bucket Implementation and Explanation

Software System Monitoring Tools

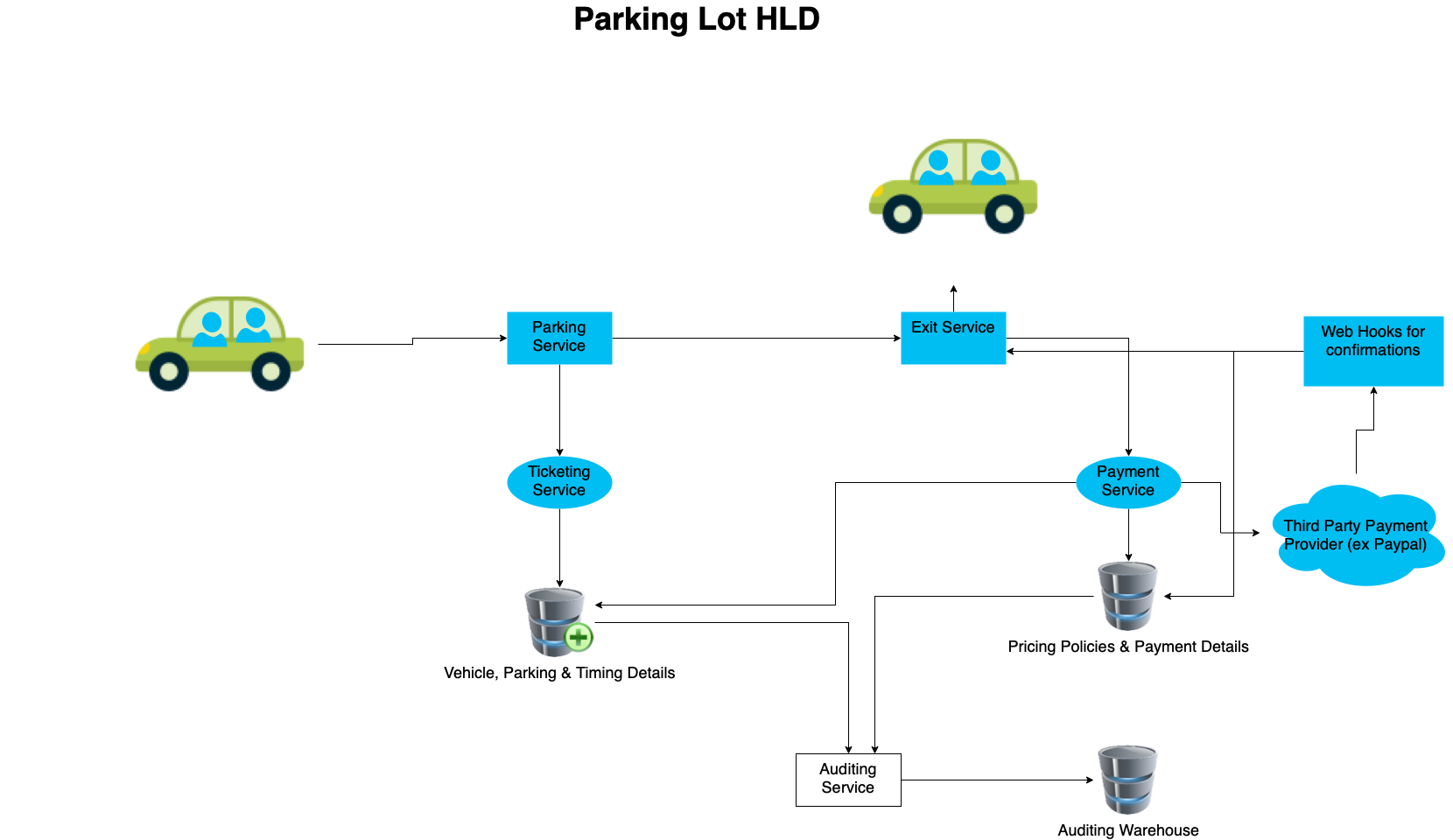
Parking Lot – System Design HLD
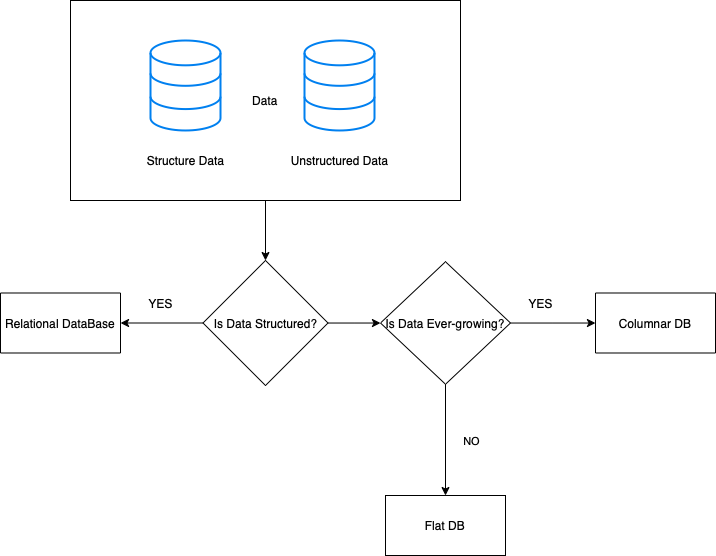
System Design – DB Choices



Pingback: Web Vitals – What are FCP, LCP, FID, TBT, TTFB? - Design Code Solve