
Introduction
A Race Conditions In Distributed Or Multithreaded System generally occurs when there are multiple threads or clients trying to access the same resource at one point of time resulting in an inconsistent, unavailable and faulty behaviour.
To understand the Race Conditions In Distributed Or Multithreaded System, we first need to understand the CAP theorem and ACID transactions. Both of them are different. But somehow, largely needed to understand the basic behaviour of distributed or multithreaded system transactions.
CAP theorem
CAP theorem stands for Consistency, Availability and Partition Tolerance.
- Consistency: Every read receives the most recent write or an error.
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
The Partition tolerance is of utmost importance in the CAP theorem and thus cannot be negotiated. So we can only provide anyone between C and A which is either Consistency or Availability. Since it can be either one of them, we have to be very cautious of the use case scenarios where which is more suitable. For Example: In financial transactions, Consistency is more important while in search, availability is more.
ACID Transaction
In multiservices architectures:
- Atomicity is an indivisible and irreducible set of operations that must all occur or none occur.
- Consistency means the transaction brings the data only from one valid state to another valid state.
- Isolation guarantees that concurrent transactions produce the same data state that sequentially executed transactions would have produced.
- Durability ensures that committed transactions remain committed even in case of system failure or power outage.
ACID transactions are more related towards the DB transaction. It should follow proper ACID transactions.
Now we have an idea about what CAP theorem and ACID transactions, which means let’s jump into how race condition occurs. You can go through our clustered and non clustered post as well.
Race Conditions In Distributed Or Multithreaded System
After applying DB per service pattern for Microservices and having multiple threads for a particular service. This problem of race condition will occur when you have multiple threads accessing the same resource across multiple services. This is a common problem in computer science and relatively easy to solve in monolithic architecture. The complexities grows when there are Microservices involved or we can say the distributed system.

There are multiple ways to solve the Race Condition, the most common one is 2PC, I am listing down the number of ways in which we can solve this:
2PC (two phase commit):
It is a distributed algorithm that coordinates all the processes that participate in a distributed atomic transaction on whether to commit or abort (roll back) the transaction. It is divided into 2 phase, mainly the request phase and commit phase. In request phase the coordinator will request all the participating resources to say yes or no for a commit, and the commit phase will commit or rollback(abort) transactions accordingly.
Optimistic Locking:
It assumes that multiple transactions can frequently complete without interfering with each other. While running, transactions use data resources without acquiring locks on those resources. Before committing, each transaction verifies that no other transaction has modified the data it has read. If the check reveals conflicting modifications, the committing transaction rolls back and can be restarted.
Pessimistic Locking:
Pessimistic Locking basically lock the file whenever a record is being modified by any user, so that no other user can save data. This prevents records from being overwritten incorrectly, but allows only one record to be processed at a time, locking out other users who need to edit records at the same time.
SAGA Pattern:
A SAGA pattern basically a sequence of transactions. Here one local transaction of a Microservices will trigger an event to notify the other service. If any of the service is failed in between because of a business rule, then a roll back procedure is followed across all the services to make it eventual consistent.
It can be implemented in two ways mainly:
1. Choreography – It doesn’t have a centrally coordinator.
2. Orchestration – It have a central coordinator.
Each pattern itself has very large implication on it. And a single line will not be justifiable for their implementation. I am trying to keep it simple and straight forward.
Bonus Knowledge about CAP theorem:
CAP theorem was further extended to PACELC theorem. It states that in case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C) (as per the CAP theorem), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C).
Below are the DB table which tell us which DB supports what.
| DDBS | P+A | P+C | E+L | E+C |
|---|---|---|---|---|
| BigTable/HBase | ||||
| Cassandra | ||||
| Cosmos DB | | |||
| Couchbase | ||||
| DynamoDB | ||||
| FaunaDB | ||||
| Hazelcast IMDG | ||||
| Megastore | ||||
| MongoDB | ||||
| MySQL Cluster | ||||
| PNUTS | ||||
| PostgreSQL | ||||
| Riak | ||||
| VoltDB/H-Store |
The Race condition can be solved more easily if we have proper documentation, and we know the end to end use case scenarios.
Make sure to go through our other content as well like:
FAQ – Race Conditions In Distributed Or Multithreaded System
References:
https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/saga/saga
https://en.wikipedia.org/wiki/CAP_theorem
https://softwareengineering.stackexchange.com/questions/403297/race-condition-in-distributed-systems



Pingback: DropBox - System Design - Thought Gem
In fact when someone doesn’t know then its up to other viewers
that they will assist, so here it happens.
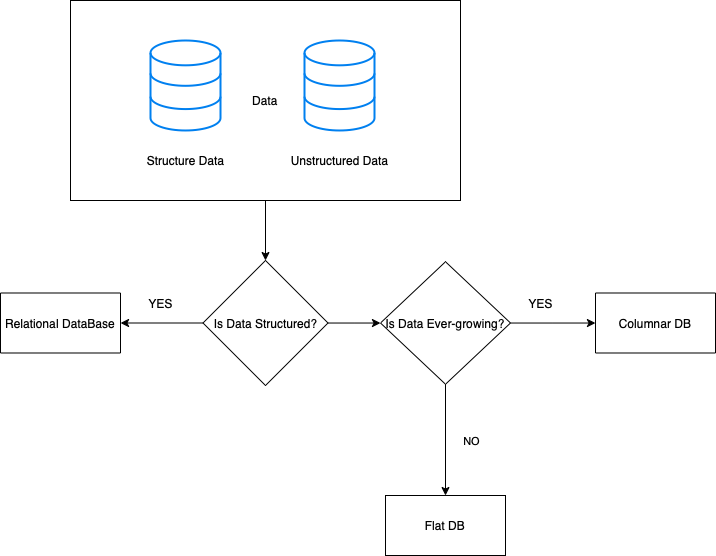
Pingback: System Design - DB Choices
An intriguing discussion is worth comment. There’s no doubt
that that you should publish more on this topic, it might not be a taboo
subject but usually people don’t speak about these subjects.
To the next! All the best!!
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You definitely know what youre talking about, why throw away your intelligence on just posting videos to your weblog when you could be giving us something enlightening to read?
Pingback: Parking Lot – System Design HLD - Thought Gem
Pingback: Rate Limiting – Token and Leaky Bucket Implementation and Explanation