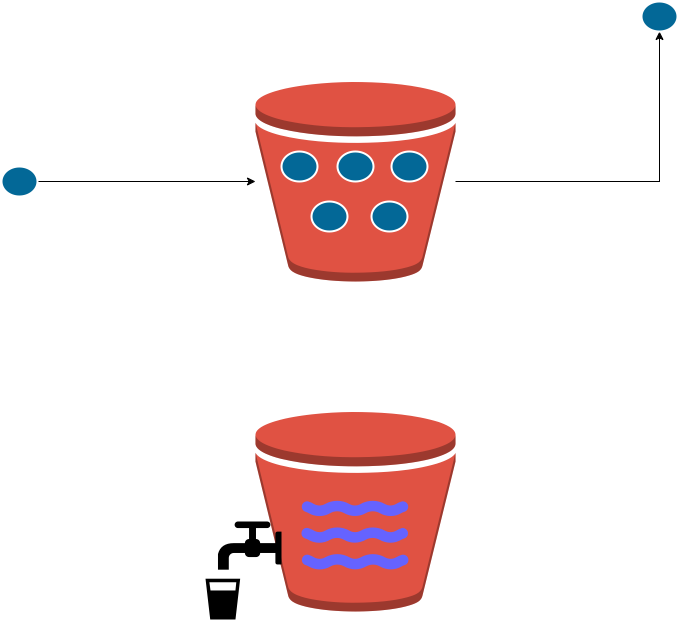
Rate Limiting – Token and Leaky Bucket Implementation and Explanation or rather rate limiting is a technique used to control the rate of traffic on a network. These are implemented using Congestive-Avoidance Algorithms (CAA), namely Token and Leaky Bucket algorithm.
What is Rate Limiting?
Rate Limiting
Dynamic and Adaptive
Dynamic Type – Leaky and Token Bucket
Adaptive Type- Adaptive QoS Algorithm.
Rate Limiting is used to regulate the flow of traffic in such a way that it does not exceed the capacity of the network.
Rate limiting can be useful in a variety of scenarios. For example, it can be used to prevent distributed denial-of-service (DDoS) attacks by limiting the amount of traffic that can be sent to a server. It can also be used to prevent abuse of an API or web service by limiting the number of requests that can be made by a single user or IP address.
There are different types of rate limiting techniques, such as token bucket and leaky bucket algorithms, which determine the rate at which requests or traffic are allowed. Some rate limiting techniques also use dynamic or adaptive rate limiting, which adjusts the rate limit based on the current state of the system or network.
Dynamic and Adaptive Rate Limiting
Dynamic and adaptive rate limiting are techniques that adjust the rate limit based on the current state of the system or network. They are used to optimize the performance of a system while preventing excessive traffic or requests.
Dynamic Rate Limiting
Dynamic rate limiting adjusts the rate limit based on the current traffic or load on the system.
For example, if the system is experiencing a high load, the rate limit can be reduced to prevent overload. Conversely, if the system is underutilized, the rate limit can be increased to allow for more traffic or requests.
Adaptive Rate Limiting
Adaptive rate limiting adjusts the rate limit based on the response time or error rate of the system.
For example, if the response time of the system is slow or the error rate is high, the rate limit can be reduced to prevent further degradation. Conversely, if the response time is fast and the error rate is low, the rate limit can be increased to allow for more traffic or requests.
Both dynamic and adaptive rate limiting can be implemented in various ways, such as through the use of software algorithms or machine learning models. They are useful in scenarios where the traffic or load on a system is highly variable or unpredictable, such as in cloud computing environments or during peak traffic periods. By adjusting the rate limit dynamically, these techniques can help ensure that a system remains performant and responsive while preventing overload or failure.
Different ways to implement Dynamic and Adaptive Rate Limits
- Reactive algorithms: An example of a reactive algorithm would be to reduce the rate limit when the system response time exceeds a certain threshold. For instance, a system that provides API services may implement a reactive algorithm that reduces the rate limit when the average response time exceeds 500 milliseconds.
- Proactive algorithms: An example of a proactive algorithm would be to increase the rate limit in anticipation of expected traffic. For example, a website that sells tickets for concerts may implement a proactive algorithm that increases the rate limit for the ticket purchase page in anticipation of high traffic during the presale period. This would prevent users from experiencing delays or timeouts when trying to purchase tickets.
- Machine learning models: An example of a machine learning model for dynamic and adaptive rate limiting would be a model trained on historical traffic patterns to predict future traffic. For example, an e-commerce website may train a machine learning model on past holiday sales data to predict traffic for the upcoming holiday season. The model can then adjust the rate limit to handle the anticipated traffic.
- Third-party solutions: An example of a third-party solution for dynamic and adaptive rate limiting would be a cloud-based service such as Amazon API Gateway. Amazon API Gateway offers built-in rate limiting features that can be configured to adjust the rate limit based on the current state of the system or network. For example, the rate limit can be increased or decreased based on the volume of incoming requests or the response time of the system.
Token and Leaky Bucket Implementation
Token bucket Rate Limiting
A token-based algorithm is a type of rate limiting algorithm that controls the rate of traffic by regulating the availability of tokens. It is a reactive algorithm.
The tokens are generated at a fixed rate and are used to permit the transmission of packets. If there are not enough tokens available, packets are not transmitted until enough tokens have accumulated. Suppose, to implement a token bucket algorithm with a limit of 5 tokens per user, you can create a map to store the number of tokens each user has accumulated, and a channel to regulate the generation of tokens. Here’s an example implementation in Go using redis at 5 request per user per minute with refill logic
package main
import (
"fmt"
"strconv"
"time"
"github.com/go-redis/redis"
)
type TokenBucket struct {
redisClient *redis.Client
maxTokens int
refillTime time.Duration
}
func NewTokenBucket(redisClient *redis.Client, maxTokens int, refillTime time.Duration) *TokenBucket {
return &TokenBucket{
redisClient: redisClient,
maxTokens: maxTokens,
refillTime: refillTime,
}
}
func (t *TokenBucket) Take(user string) bool {
// Get the current token count and last refill time for the user
result, err := t.redisClient.MGet(fmt.Sprintf("%s_tokens", user), fmt.Sprintf("%s_last_refill", user)).Result()
if err != nil {
panic(err)
}
// Parse the token count and last refill time from the Redis result
tokenCount, _ := strconv.Atoi(result[0].(string))
lastRefillTime, _ := time.Parse(time.RFC3339Nano, result[1].(string))
// Calculate the time elapsed since the last refill
timeSinceRefill := time.Since(lastRefillTime)
// Calculate the number of tokens to refill based on the elapsed time and refill rate
refillCount := int(timeSinceRefill / t.refillTime)
// Refill the token count up to the maximum
tokenCount = tokenCount + refillCount
if tokenCount > t.maxTokens {
tokenCount = t.maxTokens
}
// Check if there are enough tokens for the request
if tokenCount > 0 {
// Update the token count in Redis and return true
err := t.redisClient.MSet(fmt.Sprintf("%s_tokens", user), tokenCount, fmt.Sprintf("%s_last_refill", user), time.Now().Format(time.RFC3339Nano)).Err()
if err != nil {
panic(err)
}
return true
} else {
// Return false if there are not enough tokens
return false
}
}
In this implementation, we use the Go Redis library to interact with Redis. The Take function first retrieves the current token count and last refill time from Redis using the MGet command. It then calculates the time elapsed since the last refill, and the number of tokens to refill based on the elapsed time and refill rate.
Next, it refills the token count up to the maximum value, and checks if there are enough tokens for the request. If there are, it updates the token count and last refill time in Redis using the MSet command and returns true. Otherwise, it returns false.
To use this implementation, you can create a Redis client and pass it to the NewTokenBucket function along with the maximum token count and refill time. You can then call the Take function with the user ID for each request to check if there are enough tokens. If there are, the function returns true and decrements the token count in Redis. If there are not, the function returns false without modifying the token count.
Leaky Bucket Rate Limiting
Leaky Bucket is a proactive algorithm as it controls the rate of packet transmission by continuously leaking packets out of the bucket at a fixed rate, irrespective of whether packets are arriving or not.
In the Leaky Bucket algorithm, the rate of packet transmission is controlled by the size of the bucket and the rate at which it leaks. If packets arrive at a faster rate than the bucket can leak them, they are dropped. This approach helps to smooth out traffic and prevents bursts of traffic from overwhelming the network.
The Leaky Bucket algorithm can be used for both incoming and outgoing traffic, and is often used in Quality of Service (QoS) implementations to prioritize certain types of traffic over others. It is a simple algorithm that can be implemented in hardware or software, and is widely used in networking devices such as routers and switches.
Here is an example implementation of the Leaky Bucket algorithm using Redis to restrict users to a maximum of 5 tokens per minute:
import (
"fmt"
"strconv"
"time"
"github.com/go-redis/redis"
)
func main() {
// create Redis client
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
// set the bucket capacity and leak rate
bucketSize := 5
leakRate := 1 // token per minute
// start a loop to handle incoming requests
for {
// get the current time in Unix seconds
now := time.Now().Unix()
// get the current token count for the user
key := "user:1"
val, err := client.Get(key).Result()
if err != nil {
// handle error
fmt.Println(err)
return
}
// convert the token count to integer
tokenCount, err := strconv.Atoi(val)
if err != nil {
// handle error
fmt.Println(err)
return
}
// calculate the number of tokens that should be in the bucket now
expectedTokens := int(now/60) * leakRate
if expectedTokens > bucketSize {
expectedTokens = bucketSize
}
// calculate the number of tokens to add to the bucket
tokensToAdd := expectedTokens - tokenCount
if tokensToAdd < 0 {
tokensToAdd = 0
}
// add tokens to the bucket
_, err = client.IncrBy(key, int64(tokensToAdd)).Result()
if err != nil {
// handle error
fmt.Println(err)
return
}
// check if the bucket has enough tokens for the request
if tokenCount >= bucketSize {
// reject the request
fmt.Println("Request rejected: user has exceeded the token limit")
} else {
// process the request
fmt.Println("Request processed successfully")
}
// sleep for 1 second before checking the next request
time.Sleep(time.Second)
}
}
In this implementation, we use Redis to store the token count for each user. We set the bucket capacity to 5 tokens and the leak rate to 1 token per minute. We then start a loop to handle incoming requests.
At each iteration of the loop, we first get the current time in Unix seconds and the current token count for the user from Redis. We then calculate the expected number of tokens in the bucket based on the current time and leak rate, and add any missing tokens to the bucket.
We then check if the token count exceeds the bucket size. If it does, we reject the request. Otherwise, we process the request and decrement the token count in Redis.
Note that this implementation assumes that requests are evenly distributed over time, and does not account for bursts of traffic. To handle bursts, we can set a larger bucket size or use a more sophisticated algorithm such as the Token Bucket algorithm.
Leaky and Token Bucket In a Nutshell
| Leaky Bucket | Token Bucket | |
|---|---|---|
| Definition | A rate limiting algorithm that controls the amount of traffic allowed to pass through a system by regulating its rate of output. | A rate limiting algorithm that regulates the rate of incoming traffic by using a token-based mechanism to control access to a shared resource. |
| Bucket Metaphor | Water leaks out of a bucket at a fixed rate, representing the rate at which traffic is allowed to flow out of the system. | Tokens are added to a bucket at a fixed rate, representing the rate at which traffic is allowed to flow into the system. |
| Operation | Traffic is allowed to flow out of the system as long as there is enough water in the bucket to accommodate it. | Traffic is allowed to flow into the system as long as there are enough tokens in the bucket to accommodate it. |
| Refill Mechanism | The leaky bucket is refilled at a constant rate, regardless of whether traffic is flowing out of the system or not. | The token bucket is refilled at a constant rate, but only if there are available tokens in the bucket. |
| Rate Limiting | The leaky bucket can enforce a strict, constant rate of traffic flow, but it may also allow bursts of traffic if the bucket has accumulated water. | The token bucket can allow bursts of traffic if the bucket has accumulated tokens, but it can also enforce a strict, constant rate of traffic flow. |
| Implementation | The leaky bucket can be implemented using a simple counter and timer mechanism, or more complex systems such as queuing and shaping mechanisms. | The token bucket can be implemented using a token-based mechanism, or more complex systems such as queuing and shaping mechanisms. |
| Advantages | Simple to implement and can handle bursty traffic patterns. | Simple to implement and can handle bursty traffic patterns. |
| Disadvantages | Can be less accurate and predictable than token bucket, and may not be suitable for applications with strict traffic shaping requirements. | Can be less accurate and predictable than leaky bucket, and may not be suitable for applications with strict traffic shaping requirements. |
| Examples of Use | Network traffic shaping, email sending limits, HTTP request rate limiting. | API request rate limiting, database query rate limiting, distributed system load balancing. |
| Fine-tuning | Parameters such as the leak rate and bucket size can be adjusted to fine-tune the algorithm. | Parameters such as the token refill rate, bucket size, and maximum allowed token rate can be adjusted to fine-tune the algorithm. |
Adaptive QoS Algorithm
Adaptive QoS (Quality of Service) Algorithm is a machine learning-based approach to implement rate limiting in network traffic. It is designed to dynamically adjust the rate limits based on the current traffic load, and it uses predictive modeling to forecast future traffic patterns.
The algorithm continuously monitors the incoming traffic and adjusts the rate limit dynamically to maintain a balance between service quality and resource utilization. This is achieved by collecting statistical data about the traffic patterns, such as packet loss rate, latency, and throughput, and using this data to predict future traffic patterns. Based on these predictions, the algorithm adjusts the rate limits to ensure that the network can handle the anticipated traffic while maintaining an acceptable level of service quality.
Adaptive QoS Algorithm is a powerful tool for managing network traffic because it can automatically adjust the rate limits in response to changing traffic patterns. This makes it possible to provide optimal service quality even during periods of high traffic load or unexpected spikes in traffic volume.
Bonus – Sliding Window
In the context of rate limiting, sliding window refers to a technique used in both token bucket and leaky bucket algorithms to track the number of tokens or bytes that have been used within a specific time period.
In a token bucket algorithm, a sliding window is used to track the number of tokens that have been consumed by requests within a fixed time interval. For example, if the rate limit is set to 10 requests per second, the bucket will be refilled with 10 tokens every second. The sliding window will then track how many tokens have been used within the last second, and reject any requests that exceed this limit.
Similarly, in a leaky bucket algorithm, a sliding window is used to track the amount of data that has been transmitted within a fixed time interval. The bucket is refilled at a constant rate, and the sliding window tracks how much data has been transmitted within the last second. If the transmission rate exceeds the capacity of the bucket, the algorithm will discard any excess data.
In both cases, the sliding window is used to enforce the rate limit by keeping track of the amount of traffic that has been sent or received within a specific time period. This allows the algorithm to enforce the rate limit in a granular and precise way, while still allowing some flexibility for bursts of traffic that fall within the limits of the sliding window.
References
https://www.techopedia.com/definition/2011/traffic-shaping.
https://www.lifewire.com/traffic-shaping-2483458
https://www.cloudflare.com/learning/security/threats/rate-limiting/.
https://www.techopedia.com/definition/29013/rate-limiting.
https://www.nginx.com/blog/rate-limiting-nginx/.
https://developers.cloudflare.com/load-balancing/understand-basics/token-bucket
https://www.geeksforgeeks.org/leaky-bucket-algorithm/
https://martin-thoma.com/token-bucket-algorithm/
Other System Design Posts:
https://designcodesolve.com/technology/race-conditions-in-distributed-or-multithreaded-system/
https://designcodesolve.com/technology/system-design-db-choices/
https://designcodesolve.com/technology/dropbox-system-design/




Pingback: Parking Lot – System Design HLD - Thought Gem